以下の続きです。


以下参考にしています。
Python NLTK: Twitter Sentiment Analysis [Natural Language Processing (NLP)]
Sentiment Analysis 感情分析
Sentiment analysis (also known as opinion mining or emotion AI) refers to the use of natural language processing, text analysis, computational linguistics, and biometrics to systematically identify, extract, quantify, and study affective states and subjective information.
From Wikipedia, the free encyclopedia
日本語版が無かったので英語版から、以下意訳です。
「Sentiment Analysis(感情分析) (opinion mining または emotion AI としても知られる) とは、感情/情緒的な状態や主観的な情報を体系的に識別し、抽出、定量化を行い研究するため、自然言語処理やテキスト分析、計算言語学、およびバイオメトリクスを使用することです。」
ここでは、nltk.corpusに用意されたtwitterのサンプルをポジティブ、ネガティブに分類する Sentiment Analysis を行います。
また、tweetの分類は、 nltk のナイーブベイズ分類器を使って行います。
ナイーブベイズ分類器については、下記2つが分かりやすいです。
機械学習ナイーブベイズ分類器のアルゴリズムを理解したのでメモ。そしてPythonで書いてみた。
Tweetサンプルの入手
nltk.corpusには、twitterのサンプルがあります。
Twitter Samples [ download | source ]
NLTK Corpora
id: twitter_samples
; size: 16007673; author: ; copyright: Copyright (C) 2015 Twitter, Inc; license: Must be used subject to Twitter Developer Agreement (https://dev.twitter.com/overview/terms/agreement);
インタラクティブモードで読み込んで中身を確認します。
>>> import nltk >>> nltk.corpus.twitter_samples <TwitterCorpusReader in 'C:\\Users\\***\\twitter_samples'> >>> type(nltk.corpus.twitter_samples) <class 'nltk.corpus.reader.twitter.TwitterCorpusReader'>
class 'nltk.corpus.reader.twitter.TwitterCorpusReader'は以下のリンクにソースがあるので、目を通します。
https://www.nltk.org/_modules/nltk/corpus/reader/twitter.html
また、自分のフォルダに移動して、jsonファイルの中身を確認します。
readmeによると、顔文字を用いてpositiveかnegativeかを分けています。
tweetの文章部分をそれぞれ読み込みます。
>>> positive_tweets = twitter_samples.strings('positive_tweets.json')
>>> len(positive_tweets)
5000
>>> positive_tweets[:5]
['#FollowFriday @France_Inte @PKuchly57 @Milipol_Paris for being top engaged members in my community this week :)', '@Lamb2ja Hey James! How odd :/ Please call our Contact Centre on 02392441234 and we will be able to assist you :) Many thanks!', '@DespiteOfficial we had a listen last night :) As You Bleed is an amazing track. When are you in Scotland?!', '@97sides CONGRATS :)', 'yeaaaah yippppy!!! my accnt verified rqst has succeed got a blue tick mark on my fb profile :) in 15 days']
>>> negative_tweets = twitter_samples.strings('negative_tweets.json')
>>> len(negative_tweets)
5000
>>> negative_tweets[:5]
['hopeless for tmr :(', "Everything in the kids section of IKEA is so cute. Shame I'm nearly 19 in 2 months :(", '@Hegelbon That heart sliding into the waste basket. :(', '“@ketchBurning: I hate Japanese call him "bani" :( :(”\n\nMe too', 'Dang starting next
week I have "work" :(']
>>> all_tweets = twitter_samples.strings('tweets.20150430-223406.json')
>>> len(all_tweets)
20000
>>> all_tweets[:5]
['RT @KirkKus: Indirect cost of the UK being in the EU is estimated to be costing Britain £170 billion per year! #BetterOffOut #UKIP', 'VIDEO: Sturgeon on post-election deals http://t.co/BTJwrpbmOY', 'RT @LabourEoin: The economy was growing 3 times faster on the day David Cameron became Prime Minister than it is today.. #BBCqt http://t.co…', 'RT @GregLauder: the UKIP east lothian candidate looks about 16 and still has an msn addy http://t.co/7eIU0c5Fm1', "RT @thesundaypeople: UKIP's housing spokesman rakes in £800k
in housing benefit from migrants. http://t.co/GVwb9Rcb4w http://t.co/c1AZxcLh…"]
無事に読み込めているようです。
Tweetを単語に分解する
TweetTokenizerを用いて、取得したtweetを単語に分解します。
class nltk.tokenize.casual.TweetTokenizer
>>> tweet_tokenizer = nltk.tokenize.TweetTokenizer(preserve_case=False, strip_handles=True, reduce_len=True) >>> for tweet in positive_tweets[:5]: ... print (tweet_tokenizer.tokenize(tweet)) ... ['#followfriday', 'for', 'being', 'top', 'engaged', 'members', 'in', 'my', 'community', 'this', 'week', ':)'] ['hey', 'james', '!', 'how', 'odd', ':/', 'please', 'call', 'our', 'contact', 'centre', 'on', '02392441234', 'and', 'we', 'will', 'be', 'able', 'to', 'assist', 'you', ':)', 'many', 'thanks', '!'] ['we', 'had', 'a', 'listen', 'last', 'night', ':)', 'as', 'you', 'bleed', 'is', 'an', 'amazing', 'track', '.', 'when', 'are', 'you', 'in', 'scotland', '?', '!'] ['congrats', ':)'] ['yeaaah', 'yipppy', '!', '!', '!', 'my', 'accnt', 'verified', 'rqst', 'has', 'succeed', 'got', 'a', 'blue', 'tick', 'mark', 'on', 'my', 'fb', 'profile', ':)', 'in', '15', 'days']
どのような単語が含まれているか可視化してみます。
>>> words = [] >>> for tweet in all_tweets: ... words += tweet_tokenizer.tokenize(tweet) ... >>> fdist = nltk.FreqDist(words) >>> fdist.plot(50)
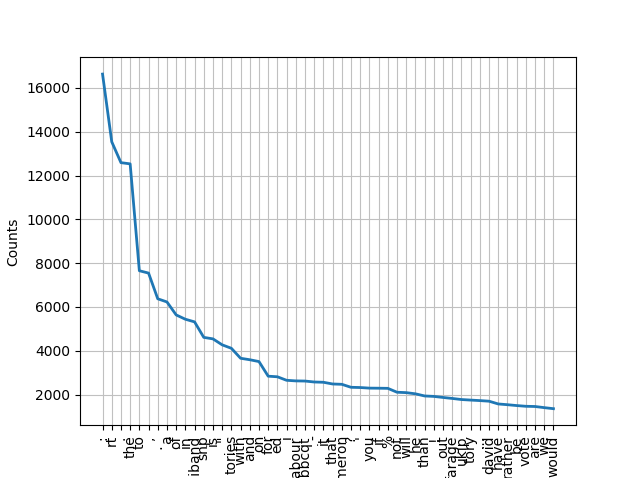
データフレームにして、どのような単語が含まれているか確認します。
>>> import pandas as pd
>>> df_fdist = pd.DataFrame(fdist.most_common(500), columns=['Word', 'Frequency'])
>>> df_fdist
Word Frequency
0 : 16631
1 rt 13540
2 . 12588
3 the 12532
4 to 7653
5 , 7546
# 省略
495 union 94
496 stand 94
497 elected 94
498 choice 94
499 cutting 93
[500 rows x 2 columns]
tweetを整形
データを確認して、下記の流れでtweetを扱いやすい形に整形します。
- “RT” から始まる部分を削除する。
- リンクを削除する。
- ハッシュタグを削除する。
- 単語に分解する。
- stopwords を取り除く。
- pos/negのラベルの判断基準となっている顔文字を取り除く。
- tweetを取得した際の基準となった単語を取り除く。
- punctuation を取り除く。
- stemに変形する。
“RT” から始まる部分を削除
正規表現を使います。
import re tweet = re.sub(r'^RT[\s]+', '', tweet)
リンクを削除
正規表現を使います。
tweet = re.sub(r'^RT[\s]+', '', tweet)
ハッシュタグを削除
正規表現を使います。
tweet = re.sub(r'#', '', tweet)
単語に分解
前節と同じように、TweetTokenizerを用います。
tokenizer = nltk.tokenize.TweetTokenizer(preserve_case=False, strip_handles=True, reduce_len=True) tweet_tokens = tokenizer.tokenize(tweet)
stopwordsを取り除く
nltk.corpus.stopwords.words('english')を用います。
>>> stopwords = nltk.corpus.stopwords.words('english')
>>> stopwords
['i', 'me', 'my', 'myself', 'we', 'our', 'ours', 'ourselves', 'you', "you're", "you've", "you'll", "you'd", 'your', 'yours', 'yourself', 'yourselves', 'he', 'him', 'his', 'himself', 'she', "she's", 'her', 'hers', 'herself', 'it', "it's", 'its', 'itself', 'they', 'them', 'their', 'theirs', 'themselves', 'what', 'which', 'who', 'whom', 'this', 'that', "that'll", 'these', 'those', 'am', 'is', 'are', 'was', 'were', 'be', 'been', 'being', 'have', 'has', 'had', 'having', 'do', 'does', 'did', 'doing', 'a', 'an', 'the', 'and', 'but', 'if', 'or', 'because', 'as', 'until', 'while', 'of', 'at', 'by', 'for', 'with', 'about', 'against', 'between', 'into', 'through', 'during', 'before', 'after', 'above', 'below', 'to', 'from', 'up', 'down', 'in', 'out', 'on', 'off', 'over', 'under', 'again', 'further', 'then', 'once', 'here', 'there', 'when', 'where', 'why', 'how', 'all', 'any', 'both', 'each', 'few', 'more', 'most', 'other', 'some', 'such', 'no', 'nor', 'not', 'only', 'own', 'same', 'so', 'than', 'too', 'very', 's', 't', 'can', 'will', 'just', 'don', "don't", 'should', "should've", 'now', 'd', 'll', 'm', 'o', 're', 've', 'y', 'ain', 'aren', "aren't", 'couldn', "couldn't", 'didn', "didn't", 'doesn', "doesn't", 'hadn', "hadn't", 'hasn', "hasn't", 'haven', "haven't", 'isn', "isn't", 'ma', 'mightn', "mightn't", 'mustn', "mustn't", 'needn', "needn't", 'shan', "shan't", 'shouldn', "shouldn't", 'wasn', "wasn't", 'weren', "weren't", 'won', "won't", 'wouldn', "wouldn't"]
>>>
顔文字を除去
twitter_samplesのREADME.txtにpos/negのラベルを付ける際に用いた顔文字があるので、それらを取り除きます。。
emoticons_happy = set([
':-)', ':)', ';)', ':o)', ':]', ':3', ':c)', ':>', '=]', '8)', '=)', ':}',
':^)', ':-D', ':D', '8-D', '8D', 'x-D', 'xD', 'X-D', 'XD', '=-D', '=D',
'=-3', '=3', ':-))', ":'-)", ":')", ':*', ':^*', '>:P', ':-P', ':P', 'X-P',
'x-p', 'xp', 'XP', ':-p', ':p', '=p', ':-b', ':b', '>:)', '>;)', '>:-)',
'<3'
])
emoticons_sad = set([
':L', ':-/', '>:/', ':S', '>:[', ':@', ':-(', ':[', ':-||', '=L', ':<',
':-[', ':-<', '=\\', '=/', '>:(', ':(', '>.<', ":'-(", ":'(", ':\\', ':-c',
':c', ':{', '>:\\', ';('
])
emoticons = emoticons_happy.union(emoticons_sad)
tweetを取得した際の基準となった単語を取り除く
同じく、twitter_samplesのREADME.txtにtweetを取得した際の基準となった単語があるので、それらを取り除きます。
keywords = "david cameron, miliband, milliband, sturgeon, clegg, farage, tory, tories, ukip, snp, libdem"
punctuationを除去
string.punctuationを用いて除去します。
>>> import string
>>> punctuations = string.punctuation
>>> punctuations
'!"#$%&\'()*+,-./:;<=>?@[\\]^_`{|}~'
語幹への変換
nltk.stem.PorterStemmer()を用いて語幹へ変換します。
Source code for nltk.stem.porter
stemmer = nltk.stem.PorterStemmer()
all_tweets に実行して確認
インタラクティブモードで実行して結果を確認します。
>>> emoticons_happy = set([
... ':-)', ':)', ';)', ':o)', ':]', ':3', ':c)', ':>', '=]', '8)', '=)', ':}',
... ':^)', ':-D', ':D', '8-D', '8D', 'x-D', 'xD', 'X-D', 'XD', '=-D', '=D',
... '=-3', '=3', ':-))', ":'-)", ":')", ':*', ':^*', '>:P', ':-P', ':P', 'X-P',
... 'x-p', 'xp', 'XP', ':-p', ':p', '=p', ':-b', ':b', '>:)', '>;)', '>:-)',
... '<3'
... ])
>>> emoticons_sad = set([
... ':L', ':-/', '>:/', ':S', '>:[', ':@', ':-(', ':[', ':-||', '=L', ':<',
... ':-[', ':-<', '=\\', '=/', '>:(', ':(', '>.<', ":'-(", ":'(", ':\\', ':-c',
... ':c', ':{', '>:\\', ';('
... ])
>>> emoticons = emoticons_happy.union(emoticons_sad)
>>>
>>> keywords = "david cameron, miliband, milliband, sturgeon, clegg, farage, tory, tories, ukip, snp, libdem"
>>>
>>> import re
>>> import string
>>> stopwords = nltk.corpus.stopwords.words('english')
>>> stemmer = nltk.stem.PorterStemmer()
>>> punctuations = string.punctuation
>>> all_tweets_clean = []
>>> for tweet in all_tweets:
... # RTから始まる部分を取り除く。
... tweet = re.sub(r'^RT[\s]+', '', tweet)
... # リンクを取り除く。
... tweet = re.sub(r'(http|https):\/\/.*[\r\n]*', '', tweet)
... # ハッシュタグを取り除く。
... tweet = re.sub(r'#', '', tweet)
... # 単語に分解する。
... tokenizer = nltk.tokenize.TweetTokenizer(preserve_case=False, strip_handles=True, reduce_len=True)
... tweet_tokens = tokenizer.tokenize(tweet)
... tweets_clean = []
... for word in tweet_tokens:
... if (word not in stopwords and # stopwordsを除去する。
... word not in emoticons and # 分類で使われている顔文字を除去する。
... word not in keywords and #検索で使われているkeywordsを除去する。
... word not in punctuations): # punctuationを除去する。
... stem_word = stemmer.stem(word) # 単語を語幹に変形する。
... tweets_clean.append(stem_word)
... all_tweets_clean += tweets_clean
...
>>> fdist_all_tweets_clean = nltk.FreqDist(all_tweets_clean)
>>> fdist_all_tweets_clean.plot(50)
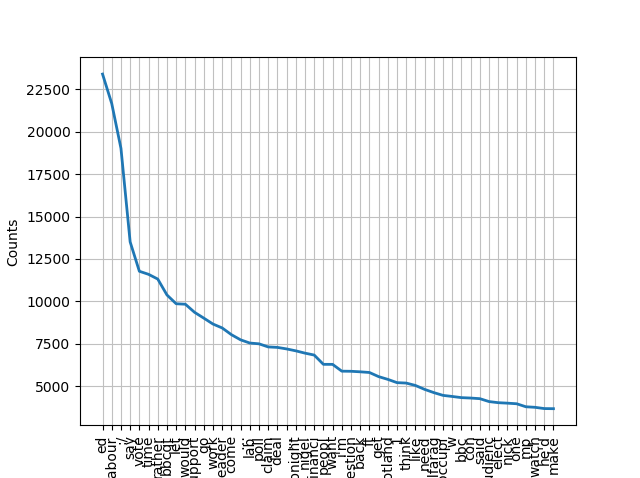
関数としてまとめる
これまでの動作を関数としてまとめ、その他の部分もコードにまとめます。
import re
import string
import nltk
# tweetの取得
twitter_samples = nltk.corpus.twitter_samples
positive_tweets = twitter_samples.strings('positive_tweets.json')
negative_tweets = twitter_samples.strings('negative_tweets.json')
all_tweets = twitter_samples.strings('tweets.20150430-223406.json')
# clean_tweetsのための変数準備
emoticons_happy = set([
':-)', ':)', ';)', ':o)', ':]', ':3', ':c)', ':>', '=]', '8)', '=)', ':}',
':^)', ':-D', ':D', '8-D', '8D', 'x-D', 'xD', 'X-D', 'XD', '=-D', '=D',
'=-3', '=3', ':-))', ":'-)", ":')", ':*', ':^*', '>:P', ':-P', ':P', 'X-P',
'x-p', 'xp', 'XP', ':-p', ':p', '=p', ':-b', ':b', '>:)', '>;)', '>:-)',
'<3'
])
emoticons_sad = set([
':L', ':-/', '>:/', ':S', '>:[', ':@', ':-(', ':[', ':-||', '=L', ':<',
':-[', ':-<', '=\\', '=/', '>:(', ':(', '>.<', ":'-(", ":'(", ':\\', ':-c',
':c', ':{', '>:\\', ';('
])
emoticons = emoticons_happy.union(emoticons_sad)
keywords = "david cameron, miliband, milliband, sturgeon, clegg, farage, tory, tories, ukip, snp, libdem"
stopwords = nltk.corpus.stopwords.words('english')
stemmer = nltk.stem.PorterStemmer()
punctuations = string.punctuation
def clean_tweets(tweet):
# RTから始まる部分を取り除く。
tweet = re.sub(r'^RT[\s]+', '', tweet)
# リンクを取り除く。
tweet = re.sub(r'(http|https):\/\/.*[\r\n]*', '', tweet)
# ハッシュタグを取り除く。
tweet = re.sub(r'#', '', tweet)
# 単語に分解する。
tokenizer = nltk.tokenize.TweetTokenizer(preserve_case=False, strip_handles=True, reduce_len=True)
tweet_tokens = tokenizer.tokenize(tweet)
tweets_clean = []
for word in tweet_tokens:
if (word not in stopwords and # stopwordsを除去する。
word not in emoticons and # 分類で使われている顔文字を除去する。
word not in keywords and #検索で使われているkeywordsを除去する。
word not in punctuations): # punctuationを除去する。
stem_word = stemmer.stem(word) # 単語を語幹に変形する。
tweets_clean.append(stem_word)
return tweets_clean
print (all_tweets[100])
print (clean_tweets(all_tweets[100]))
Bag Of Words
BOW(Bag of Words)を作成します。
The bag-of-words model is a simplifying representation used in natural language processing and information retrieval (IR). In this model, a text (such as a sentence or a document) is represented as the bag (multiset) of its words, disregarding grammar and even word order but keeping multiplicity.
From Wikipedia, the free encyclopedia
以下意訳です。
「BOWモデルは、自然言語処理および情報検索(IR)で使用されます。 このモデルでは、文章や文書などのテキストを、文法や単語の並び順は無視し、多重度は保ちながら、その単語を詰めたBag(袋)として表現されます。」
scikit-learn を使って tf–idf で特徴量を抜き出す方がベターかと思いますが、簡易的に、Trueで単語の存在だけを特徴量として抜き出すことにします。
def bag_of_words(tweet):
''' tweetを単語に分解し、bowを返す。'''
words = clean_tweets(tweet)
words_dictionary = dict([word, True] for word in words)
return words_dictionary
for tweet in positive_tweets[:5]:
print (bag_of_words(tweet))
# {'followfriday': True, 'top': True, 'engag': True, 'member': True, 'commun': True, 'week': True}
# {'hey': True, 'jame': True, 'odd': True, ':/': True, 'pleas': True, 'call': True, 'contact': True, 'centr': True, '02392441234': True, 'abl': True, 'assist': True, 'mani': True, 'thank': True}
# {'listen': True, 'last': True, 'night': True, 'bleed': True, 'amaz': True, 'track': True, 'scotland': True}
# {'congrat': True}
# {'yeaaah': True, 'yipppi': True, 'accnt': True, 'verifi': True, 'rqst': True, 'succeed': True, 'got': True, 'blue': True, 'tick': True, 'mark': True, 'fb': True, 'profil': True, '15': True, 'day': True}
以下の動画は、文章からの特徴量の導出について分かりやすく説明しています。
データセットの作成
positive tweets と negative tweets のデータセットを作成します。
それぞれ、テスト用データセット1000個と学習用データセット4000個に分割して、2000個のテスト用データと8000個の学習データを作成します。
# positive tweets set
positive_tweets_set = []
for tweet in positive_tweets:
positive_tweets_set.append((bag_of_words(tweet), 'pos'))
# negative tweets set
negative_tweets_set = []
for tweet in negative_tweets:
negative_tweets_set.append((bag_of_words(tweet), 'neg'))
import random
random.shuffle(positive_tweets_set)
random.shuffle(negative_tweets_set)
test_set = positive_tweets_set[:1000] + negative_tweets_set[:1000]
train_set = positive_tweets_set[1000:] + negative_tweets_set[1000:]
# 2000
print(len(test_set))
# ({'realli': True, 'good': True, 'luck': True}, 'pos')
print(test_set[0])
# 8000
print(len(train_set))
# ({'smart': True}, 'pos')
print(train_set[0])
ナイーブベイズ分類器の作成
ナイーブベイズ分類器を作成して結果を確認、保存します。
# 学習
classifier = nltk.NaiveBayesClassifier.train(train_set)
print (classifier.show_most_informative_features(10))
# Most Informative Features
# via = True pos : neg = 34.3 : 1.0
# glad = True pos : neg = 23.7 : 1.0
# sad = True neg : pos = 21.2 : 1.0
# x15 = True neg : pos = 19.7 : 1.0
# appreci = True pos : neg = 17.7 : 1.0
# ugh = True neg : pos = 17.0 : 1.0
# arriv = True pos : neg = 15.3 : 1.0
# blog = True pos : neg = 14.3 : 1.0
# perfect = True pos : neg = 14.3 : 1.0
# ff = True pos : neg = 14.2 : 1.0
# テスト
accuracy = nltk.classify.accuracy(classifier, test_set)
print(accuracy)
# Output: 0.7525
# naivebayes分類器の保存
save_classifier = open("naivebayes.pickle","wb")
pickle.dump(classifier, save_classifier)
save_classifier.close()
# # naivebayes分類器の読み込み
# classifier_f = open("naivebayes.pickle", "rb")
# classifier = pickle.load(classifier_f)
# classifier_f.close()
分類器の評価
具体的なtweetを与えてみる
分かりやすい具体的なtweet例を与えて、正しく分類できているか確認します。
## 明らかにnegな例
custom_tweet = "It was a disaster. No link with the originals. Ridiculous. Nuff said."
custom_tweet_set = bag_of_words(custom_tweet)
print (classifier.classify(custom_tweet_set))
# neg
# 正しく分類できている。
# probability result
prob_result = classifier.prob_classify(custom_tweet_set)
print (prob_result)
# Output: <ProbDist with 2 samples>
print (prob_result.max())
# Output: neg
print (prob_result.prob("neg"))
# Output: 0.9108711492983692
print (prob_result.prob("pos"))
# Output: 0.08912885070163097
## 明らかにposな例
custom_tweet = "I saw this movie and loved it - favorite thing I saw. It was so moving & real. The entire cast was terrific.."
custom_tweet_set = bag_of_words(custom_tweet)
print (classifier.classify(custom_tweet_set))
# pos
# 正しく分類できている。
# probability result
prob_result = classifier.prob_classify(custom_tweet_set)
print (prob_result)
# Output: <ProbDist with 2 samples>
print (prob_result.max())
# Output: pos
print (prob_result.prob("neg"))
# Output: 0.0009500835088238353
print (prob_result.prob("pos"))
# Output: 0.9990499164911743
できているようです。
混同行列(Confusion Matrix)とF値
それぞれ、nltkのモジュールを用いて、簡単に導出できます。
混同行列(Confusion Matrix)
In the field of machine learning and specifically the problem of statistical classification, a confusion matrix, also known as an error matrix,[4] is a specific table layout that allows visualization of the performance of an algorithm
From Wikipedia, the free encyclopedia
機械学習の分野、特に統計的に分類を行う際に、アルゴリズムの性能をわかりやすく視覚化できます。
wikipediaの以下の例が分かりやすいです。
猫8匹、犬6匹、ウサギ11匹を分類器に分類させたところ、以下のような結果になったとします。
| Actual class | ||||
|---|---|---|---|---|
| Cat | Dog | Rabbit | ||
Predicted
class |
Cat | 5 | 2 | 0 |
| Dog | 3 | 3 | 2 | |
| Rabbit | 0 | 1 | 11 | |
この時、猫かどうかの混同行列(Confusion Matrix)は以下のようになります。
| Actual class | ||||
|---|---|---|---|---|
| Cat | Non-cat | |||
Predicted
class |
Cat | 5 True Positives | 2 False Positives | |
| Non-cat | 3 False Negatives | 17 True Negatives | ||
from collections import defaultdict
actual_set = defaultdict(set)
predicted_set = defaultdict(set)
actual_set_cm = []
predicted_set_cm = []
for index, (feature, actual_label) in enumerate(test_set):
actual_set[actual_label].add(index)
actual_set_cm.append(actual_label)
predicted_label = classifier.classify(feature)
predicted_set[predicted_label].add(index)
predicted_set_cm.append(predicted_label)
from nltk.metrics import ConfusionMatrix
cm = ConfusionMatrix(actual_set_cm, predicted_set_cm)
print (cm)
# | n p |
# | e o |
# | g s |
# ----+---------+
# neg |<733>267 |
# pos | 257<743>|
# ----+---------+
# (row = reference; col = test)
print (cm.pretty_format(sort_by_count=True, show_percents=True, truncate=9))
# | n p |
# | e o |
# | g s |
# ----+---------------+
# neg | <36.6%> 13.3% |
# pos | 12.8% <37.1%>|
# ----+---------------+
# (row = reference; col = test)
F値
F値を計算します。
In statistical analysis of binary classification, the F1 score (also F-score or F-measure) is a measure of a test’s accuracy.
From Wikipedia, the free encyclopedia
F値 は、0から1の間で1に近いほど良い精度と考えられます。
F値がどんな値かは、以下の説明が大変分かりやすいです。
from nltk.metrics import f_measure
print('pos F-measure:', f_measure(actual_set['pos'], predicted_set['pos']))
# pos F-measure: 0.7470119521912351
print('neg F-measure:', f_measure(actual_set['neg'], predicted_set['neg']))
# pos F-measure: 0.7470119521912351