現代ポートフォリオ理論では、リスクとして分散を使いました。

バリュー・アット・リスクは、正規分布を仮定しリスクを損失に限定することで、より一般感覚に近いリスクを表現することができます。
バリュー・アット・リスク
バリュー・アット・リスク(Value at Risk、 VaR)とは、リスク分析の手法の一つ。現有資産の損失可能性を時価推移より測定する分析指標。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
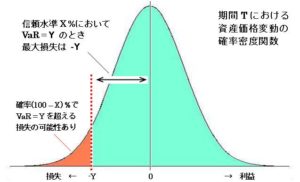
バリュー・アット・リスクは、過去のデータから平均\(\mu\)と分散\(\sigma\)を求め、正規分布\(N(\mu, \sigma^2)\)に従うとして、信頼水準\(c\)での最大の損失損失\(VaR\)は、以下のように定義されます。
$$ Prob (\delta \pi \leq -VaR) = 1-c $$
{kind=link}
つまり、\(S\)を現在の資産とすると、\(\alpha(1-c) \)を標準正規分布の累積分布関数の逆関数として、\(VaR\)は以下のように求めることが出来ます。
$$ VaR = S \cdot [ \mu – \sigma \cdot \alpha(1-c)] $$
また、\(\mu\)、\(\sigma\)を日次で求め日次の\(VaR\)を計算する場合は以上で求まりますが、もし\(n\)日の \(VaR\)を求めるときは\(\mu\)、\(\sigma\) を以下のように変換します。
$$ \mu_{ndays} = n \cdot \mu_{daily} $$
$$ \sigma_{ndays} = \sqrt{n} \cdot \sigma_{daily} $$
Pythonで実装
Python で実装します。
正規分布の累積分布関数の逆関数は、scipy.stats.norm で簡単に求めることができます。
import datetime
import numpy as np
import pandas as pd
from scipy.stats import norm
from pandas_datareader import data as pdr
import yfinance as yf
import requests_cache
# override pandas_datareader
yf.pdr_override()
# casche for downloaded data
expire_after = datetime.timedelta(days=3)
session = requests_cache.CachedSession(cache_name='cache', backend='sqlite', expire_after=expire_after)
def download_data_adjclose(stock, start, end):
data = pdr.get_data_yahoo(stock, start, end)['Adj Close']
return data
def calc_daily_pct_change(data):
pct_change = data.pct_change()
return pct_change
class ValueAtRisk(object):
def __init__(self, s, c, n= 1, stock='GOOGL', start='2015-01-01', end='2020-01-01'):
self.s = s
self.c = c
start = pd.to_datetime(start)
end = pd.to_datetime(end)
data = download_data_adjclose(stock, start, end)
pct_change = calc_daily_pct_change(data)
self.mu = np.mean(pct_change) * n
self.sigma = np.std(pct_change) * np.sqrt(n)
def calc(self):
alpha = norm.ppf(1-self.c)
var = self.s * (self.mu - self.sigma*alpha)
return var
if __name__ == '__main__':
s = 1000000
c = 0.99
value_at_risk = ValueAtRisk(s, c)
# 35662.65269757571
print(value_at_risk.calc())
モンテカルロ法でのシミュレーション
モンテカルロ法でVaRを求めます。
幾何ブラウン運動の解を使い株価変動をシミュレートします。
$$ S_{t}=S_{0}\exp \left(\left(\mu -{\frac {\sigma ^{2}}{2}}\right)t+\sigma B_{t}\right) $$
import datetime
import numpy as np
import pandas as pd
from scipy.stats import norm
from pandas_datareader import data as pdr
import yfinance as yf
import requests_cache
# override pandas_datareader
yf.pdr_override()
# casche for downloaded data
expire_after = datetime.timedelta(days=3)
session = requests_cache.CachedSession(cache_name='cache', backend='sqlite', expire_after=expire_after)
def download_data_adjclose(stock, start, end):
data = pdr.get_data_yahoo(stock, start, end)['Adj Close']
return data
def calc_daily_pct_change(data):
pct_change = data.pct_change()
return pct_change
class ValueAtRisk(object):
def __init__(self, s, c, n= 1, stock='GOOGL', start='2015-01-01', end='2020-01-01'):
self.s = s
self.c = c
start = pd.to_datetime(start)
end = pd.to_datetime(end)
data = download_data_adjclose(stock, start, end)
pct_change = calc_daily_pct_change(data)
self.mu = np.mean(pct_change) * n
self.sigma = np.std(pct_change) * np.sqrt(n)
def calc(self):
alpha = norm.ppf(1-self.c)
var = self.s * (self.mu - self.sigma*alpha)
return var
def monte_carlo(self, iterations=100000):
np.random.seed(seed=0)
# generate stock prices
rands = np.random.normal(0, 1, [1, iterations])
stock_prices = self.s * np.exp((self.mu-0.5*self.sigma**2) + self.sigma*rands)
# sort an array of stock_prices and get (1-self.c)*100 percentile
# e.x. VaR with 99% confidence level, there is left 1% probability less than VaR.
stock_prices.sort()
percentile = np.percentile(stock_prices, (1-self.c)*100)
return self.s - percentile
if __name__ == '__main__':
s = 1000000
c = 0.99
value_at_risk = ValueAtRisk(s, c)
# 35662.65269757571
print(value_at_risk.calc())
# 33607.08215287316
print(value_at_risk.monte_carlo())