以下の続きです。

nltkeのモジュールと不思議の国のアリスを読み込みます。
>>> import nltk
>>> from nltk.text import Text
>>> alice = Text(nltk.corpus.gutenberg.words('carroll-alice.txt'))
>>> fdist = nltk.FreqDist(alice)
孤語と連語
孤語
fdistオブジェクトのhapaxesメソッドを使うことで、孤語を表示します。
長いので途中省略しています。
孤語(こご)、ないし、ハパックス・レゴメノン(hapax legomenon、 ([ˈhæpəks
lɪˈɡɒmɪnɒn]、[ˈhæpæks]、[ˈheɪpæks][1][2]、複数形はハパックス・レゴメナ (pl. hapax legomena)、hapax (pl. hapaxes) と略記)は、コーパス言語学において、ある言語で書き記されたすべてのテキスト全体なり、特定の作家の作品群や、特定のひとつのテキストの中など、一定の文脈の中で、1回だけ出現する単語である。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
>>> print(fdist.hapaxes()) ['Lewis', 'Carroll', '1865', ']', 'Hole', ...(省略)... 'sorrows', 'joys', 'remembering', 'happy']
連語
Textオブジェクトのcollocationsメソッドを使うことで、連語を表示します。
連語(れんご、英: Collocation)は一般に、複数の単語からなるが、まとまった形で単語と同様に用いられる言語表現をいう。…
コーパス言語学では、有意に高い確率で共起する語の組み合わせを「連語」という。これには(1)の意味の「連語」や一部の慣用句などを含みうるが、別の概念である。
出典: フリー百科事典『ウィキペディア(Wikipedia)』
>>> print(alice.collocations()) Mock Turtle; said Alice; March Hare; White Rabbit; thought Alice; golden key; beautiful Soup; white kid; good deal; kid gloves; Mary Ann; yer honour; three gardeners; play croquet; Lobster Quadrille; ootiful Soo; great hurry; old fellow; trembling voice; poor little None
nltk.corpus に含まれるテキストの文字・単語・文
文字
nltk.corpusに含まれる文章は、.rawメソッドで全ての文字を取得できます。
>>> alice_chars = nltk.corpus.gutenberg.raw('carroll-alice.txt')
>>> print(alice_chars)
...(省略)...
Lastly, she pictured to herself how this same little sister of hers
would, in the after-time, be herself a grown woman; and how she would
keep, through all her riper years, the simple and loving heart of her
childhood: and how she would gather about her other little children, and
make THEIR eyes bright and eager with many a strange tale, perhaps even
with the dream of Wonderland of long ago: and how she would feel with
all their simple sorrows, and find a pleasure in all their simple joys,
remembering her own child-life, and the happy summer days.
単語
nltk.corpusに含まれる文章は、 .wordsメソッドで全ての単語をリストで取得できます。リストなのでpythonが自動的に省略して表示します。
>>> alice_words = nltk.corpus.gutenberg.words('carroll-alice.txt')
>>> print(alice_words)
['[', 'Alice', "'", 's', 'Adventures', 'in', ...]
文
nltk.corpusに含まれる文章は、 .sentsメソッドで全ての文をリストで取得できます。文のリストの中では単語がリストになっています。
>>> alice_sents = nltk.corpus.gutenberg.sents('carroll-alice.txt')
>>> print(alice_sents)
[['[', 'Alice', "'", 's', 'Adventures', 'in', 'Wonderland', 'by', 'Lewis', 'Carroll', '1865', ']'], ['CHAPTER', 'I', '.'], ...]
単語に含まれる文字数の平均
上のメソッドを使うことで、単語に含まれる文字数の平均が簡単に求まります。
>>> print(int(len(alice_chars) / len(alice_words))) 4
関数として定義しておきます。
>>> def avg_word_len(num_chars, num_words): ... return int(num_chars / num_words) ...
文に含まれる単語数の平均
また、文に含まれる単語数の平均も簡単に求まります。
>>> print(int(len(alice_words) / len(alice_sents))) 20
関数として定義しておきます。
>>> def avg_sent_len(num_words, num_sents): ... return int(num_words / num_sents) ...
nltk.corpus.gutenbergに含まれる文章の平均文字数、平均単語数
上で定義した関数を使って、nltk.corpus.gutenbergに含まれる文章の平均文字数、平均単語数を求めてみます。
>>> for file_id in nltk.corpus.gutenberg.fileids(): ... num_chars = len(nltk.corpus.gutenberg.raw(file_id)) ... num_words = len(nltk.corpus.gutenberg.words(file_id)) ... num_sents = len(nltk.corpus.gutenberg.sents(file_id)) ... print(file_id + ' : 平均文字数/単語 ' + str(avg_word_len(num_chars, num_words)) + ' 平均単語数/文 ' + str(avg_sent_len(num_words, num_sents))) ... austen-emma.txt : 平均文字数/単語 4 平均単語数/文 24 austen-persuasion.txt : 平均文字数/単語 4 平均単語数/文 26 austen-sense.txt : 平均文字数/単語 4 平均単語数/文 28 bible-kjv.txt : 平均文字数/単語 4 平均単語数/文 33 blake-poems.txt : 平均文字数/単語 4 平均単語数/文 19 bryant-stories.txt : 平均文字数/単語 4 平均単語数/文 19 burgess-busterbrown.txt : 平均文字数/単語 4 平均単語数/文 17 carroll-alice.txt : 平均文字数/単語 4 平均単語数/文 20 chesterton-ball.txt : 平均文字数/単語 4 平均単語数/文 20 chesterton-brown.txt : 平均文字数/単語 4 平均単語数/文 22 chesterton-thursday.txt : 平均文字数/単語 4 平均単語数/文 18 edgeworth-parents.txt : 平均文字数/単語 4 平均単語数/文 20 melville-moby_dick.txt : 平均文字数/単語 4 平均単語数/文 25 milton-paradise.txt : 平均文字数/単語 4 平均単語数/文 52 shakespeare-caesar.txt : 平均文字数/単語 4 平均単語数/文 11 shakespeare-hamlet.txt : 平均文字数/単語 4 平均単語数/文 12 shakespeare-macbeth.txt : 平均文字数/単語 4 平均単語数/文 12 whitman-leaves.txt : 平均文字数/単語 4 平均単語数/文 36
WEB上の文章の読み込み
urllibを使ってweb上の文章を読み込み、NLTKの分析の対象にしてみます。
まずは、urllibをインポートします。
import urllib
gutenbergのサイトからガリバー旅行記を読み込んでみます。
url = "http://www.gutenberg.org/cache/epub/17157/pg17157.txt"
raw = urllib.request.urlopen(url).read().decode('utf-8')
読み込んだガリバー旅行記をTextオブジェクトに変換します。
>>> gullivers_travels = nltk.Text(nltk.word_tokenize(raw))
Textオブジェクトにすることで、NLTKを用いたこれまでと同じような分析を行うことができます。 例えば、以下のようにすることで孤語を求めることができます。
>>> fdist_gulliver = nltk.FreqDist(gullivers_travels) >>> print(fdist_gulliver.hapaxes())
nltk.corpus.webtext
gutenbergからの文章だけでなく、corpusにはwebtextという文章も含まれています。
Web Text Corpusどのような文章があるか確認します。
>>> for file_id in nltk.corpus.webtext.fileids(): ... print(file_id) ... firefox.txt grail.txt overheard.txt pirates.txt singles.txt wine.txt
gutenbergと同じくcorpusに含まれている文章なので、 nltk.corpus に含まれるテキストの文字・単語・文のメソッドを使うことができます。
>>> num_grail_words = len(nltk.corpus.webtext.words('grail.txt'))
>>> num_grail_chars = len(nltk.corpus.webtext.raw('grail.txt'))
>>> num_grail_sents = len(nltk.corpus.webtext.sents('grail.txt'))
>>>
>>> print(avg_word_len(num_grail_chars, num_grail_words))
3
>>> print(avg_sent_len(num_grail_words, num_grail_sents))
9
nltk.corpus.inaugural
courpsにはアメリカ大統領の就任演説も含まれています。
>>> for file_id in nltk.corpus.inaugural.fileids(): ... print(file_id) ... 1789-Washington.txt 1793-Washington.txt 1797-Adams.txt 1801-Jefferson.txt 1805-Jefferson.txt 1809-Madison.txt 1813-Madison.txt 1817-Monroe.txt 1821-Monroe.txt 1825-Adams.txt 1829-Jackson.txt 1833-Jackson.txt 1837-VanBuren.txt 1841-Harrison.txt 1845-Polk.txt 1849-Taylor.txt 1853-Pierce.txt 1857-Buchanan.txt 1861-Lincoln.txt 1865-Lincoln.txt 1869-Grant.txt 1873-Grant.txt 1877-Hayes.txt 1881-Garfield.txt 1885-Cleveland.txt 1889-Harrison.txt 1893-Cleveland.txt 1897-McKinley.txt 1901-McKinley.txt 1905-Roosevelt.txt 1909-Taft.txt 1913-Wilson.txt 1917-Wilson.txt 1921-Harding.txt 1925-Coolidge.txt 1929-Hoover.txt 1933-Roosevelt.txt 1937-Roosevelt.txt 1941-Roosevelt.txt 1945-Roosevelt.txt 1949-Truman.txt 1953-Eisenhower.txt 1957-Eisenhower.txt 1961-Kennedy.txt 1965-Johnson.txt 1969-Nixon.txt 1973-Nixon.txt 1977-Carter.txt 1981-Reagan.txt 1985-Reagan.txt 1989-Bush.txt 1993-Clinton.txt 1997-Clinton.txt 2001-Bush.txt 2005-Bush.txt 2009-Obama.txt
就任演説で “america” と言った回数を数えてみます。 “america”から始まる単語にすることで、 “american” といった単語も含みます。
>>> for fileid in nltk.corpus.inaugural.fileids():
... america_count = 0
... for w in nltk.corpus.inaugural.words(fileid):
... if w.lower().startswith('america'):
... america_count += 1
... president = fileid[5:-4]
... year = fileid[:4]
... print('大統領:' + president + ' 就任した年:' + year + " 就任演説でアメリカと言った回数:" + str(america_count))
...
大統領:Washington 就任した年:1789 就任演説でアメリカと言った回数:2
大統領:Washington 就任した年:1793 就任演説でアメリカと言った回数:1
大統領:Adams 就任した年:1797 就任演説でアメリカと言った回数:8
大統領:Jefferson 就任した年:1801 就任演説でアメリカと言った回数:0
大統領:Jefferson 就任した年:1805 就任演説でアメリカと言った回数:1
大統領:Madison 就任した年:1809 就任演説でアメリカと言った回数:0
大統領:Madison 就任した年:1813 就任演説でアメリカと言った回数:1
大統領:Monroe 就任した年:1817 就任演説でアメリカと言った回数:1
大統領:Monroe 就任した年:1821 就任演説でアメリカと言った回数:2
大統領:Adams 就任した年:1825 就任演説でアメリカと言った回数:0
大統領:Jackson 就任した年:1829 就任演説でアメリカと言った回数:0
大統領:Jackson 就任した年:1833 就任演説でアメリカと言った回数:2
大統領:VanBuren 就任した年:1837 就任演説でアメリカと言った回数:2
大統領:Harrison 就任した年:1841 就任演説でアメリカと言った回数:7
大統領:Polk 就任した年:1845 就任演説でアメリカと言った回数:0
大統領:Taylor 就任した年:1849 就任演説でアメリカと言った回数:2
大統領:Pierce 就任した年:1853 就任演説でアメリカと言った回数:2
大統領:Buchanan 就任した年:1857 就任演説でアメリカと言った回数:3
大統領:Lincoln 就任した年:1861 就任演説でアメリカと言った回数:2
大統領:Lincoln 就任した年:1865 就任演説でアメリカと言った回数:1
大統領:Grant 就任した年:1869 就任演説でアメリカと言った回数:0
大統領:Grant 就任した年:1873 就任演説でアメリカと言った回数:0
大統領:Hayes 就任した年:1877 就任演説でアメリカと言った回数:1
大統領:Garfield 就任した年:1881 就任演説でアメリカと言った回数:2
大統領:Cleveland 就任した年:1885 就任演説でアメリカと言った回数:4
大統領:Harrison 就任した年:1889 就任演説でアメリカと言った回数:6
大統領:Cleveland 就任した年:1893 就任演説でアメリカと言った回数:9
大統領:McKinley 就任した年:1897 就任演説でアメリカと言った回数:9
大統領:McKinley 就任した年:1901 就任演説でアメリカと言った回数:7
大統領:Roosevelt 就任した年:1905 就任演説でアメリカと言った回数:0
大統領:Taft 就任した年:1909 就任演説でアメリカと言った回数:12
大統領:Wilson 就任した年:1913 就任演説でアメリカと言った回数:0
大統領:Wilson 就任した年:1917 就任演説でアメリカと言った回数:4
大統領:Harding 就任した年:1921 就任演説でアメリカと言った回数:24
大統領:Coolidge 就任した年:1925 就任演説でアメリカと言った回数:11
大統領:Hoover 就任した年:1929 就任演説でアメリカと言った回数:12
大統領:Roosevelt 就任した年:1933 就任演説でアメリカと言った回数:2
大統領:Roosevelt 就任した年:1937 就任演説でアメリカと言った回数:5
大統領:Roosevelt 就任した年:1941 就任演説でアメリカと言った回数:12
大統領:Roosevelt 就任した年:1945 就任演説でアメリカと言った回数:2
大統領:Truman 就任した年:1949 就任演説でアメリカと言った回数:4
大統領:Eisenhower 就任した年:1953 就任演説でアメリカと言った回数:6
大統領:Eisenhower 就任した年:1957 就任演説でアメリカと言った回数:7
大統領:Kennedy 就任した年:1961 就任演説でアメリカと言った回数:7
大統領:Johnson 就任した年:1965 就任演説でアメリカと言った回数:10
大統領:Nixon 就任した年:1969 就任演説でアメリカと言った回数:10
大統領:Nixon 就任した年:1973 就任演説でアメリカと言った回数:23
大統領:Carter 就任した年:1977 就任演説でアメリカと言った回数:5
大統領:Reagan 就任した年:1981 就任演説でアメリカと言った回数:16
大統領:Reagan 就任した年:1985 就任演説でアメリカと言った回数:21
大統領:Bush 就任した年:1989 就任演説でアメリカと言った回数:11
大統領:Clinton 就任した年:1993 就任演説でアメリカと言った回数:33
大統領:Clinton 就任した年:1997 就任演説でアメリカと言った回数:31
大統領:Bush 就任した年:2001 就任演説でアメリカと言った回数:20
大統領:Bush 就任した年:2005 就任演説でアメリカと言った回数:30
大統領:Obama 就任した年:2009 就任演説でアメリカと言った回数:15
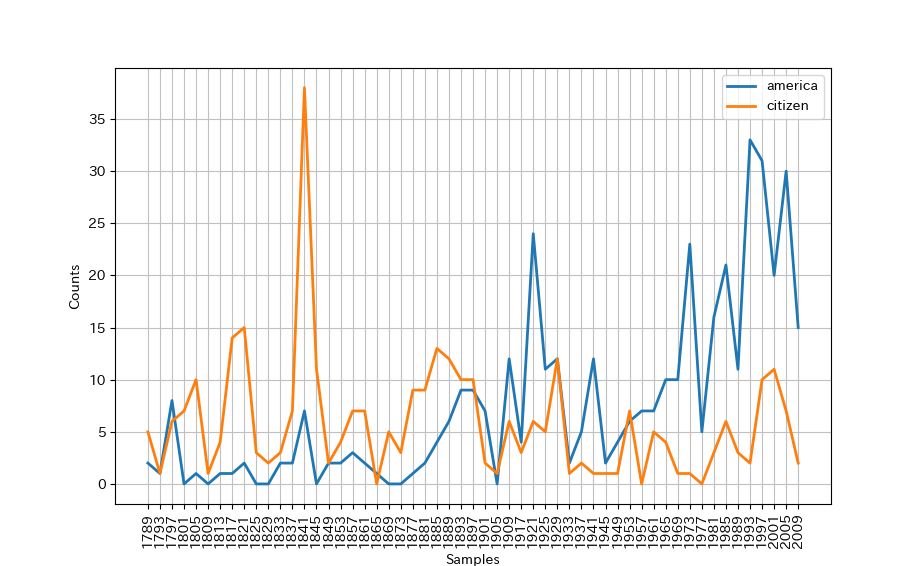
ConditionalFreqDist というメソッドを使うことで、就任演説に “america” と”citizen” という単語が含まれる回数を数え、図にプロットしてみます。
>>> cfd = nltk.ConditionalFreqDist( ... (target, fileid[:4]) ... for fileid in nltk.corpus.inaugural.fileids() ... for w in nltk.corpus.inaugural.words(fileid) ... for target in ['america', 'citizen'] ... if w.lower().startswith(target) ... ) >>> cfd.plot()